
-
findBy*** VS findBy***Id카테고리 없음 2022. 10. 4. 21:44
속닥속닥 프로젝트에서는 Spring Data Jpa 를 사용하고 있다. 추상화된 api 를 쓰다 보니, 예상치 못한 부분에서 성능 이슈가 발생하기도 하는데, 이번에 댓글 기능 리팩터링을 하며 겪은 문제를 써보고자 한다.
문제 상황
속닥속닥에는 댓글 기능이 있는데, 게시글 하나에 댓글 여러개가 속할 수 있기 때문에 Many To One 으로 연관관계를 맺고 있다. 다시 말해, Comment 테이블에서 post_id 를 가지고 있는 것이다.
이 상황에서 CommentRepository 에서 findAllByPostId 메서드를 호출하면, 당연히 아래와 같은 쿼리가 나갈줄 알았다.
select * from comment as c where c.post_id = ?그런데... 실제로 실행을 해보고 나니 아래와 같은 쿼리가 나왔다.
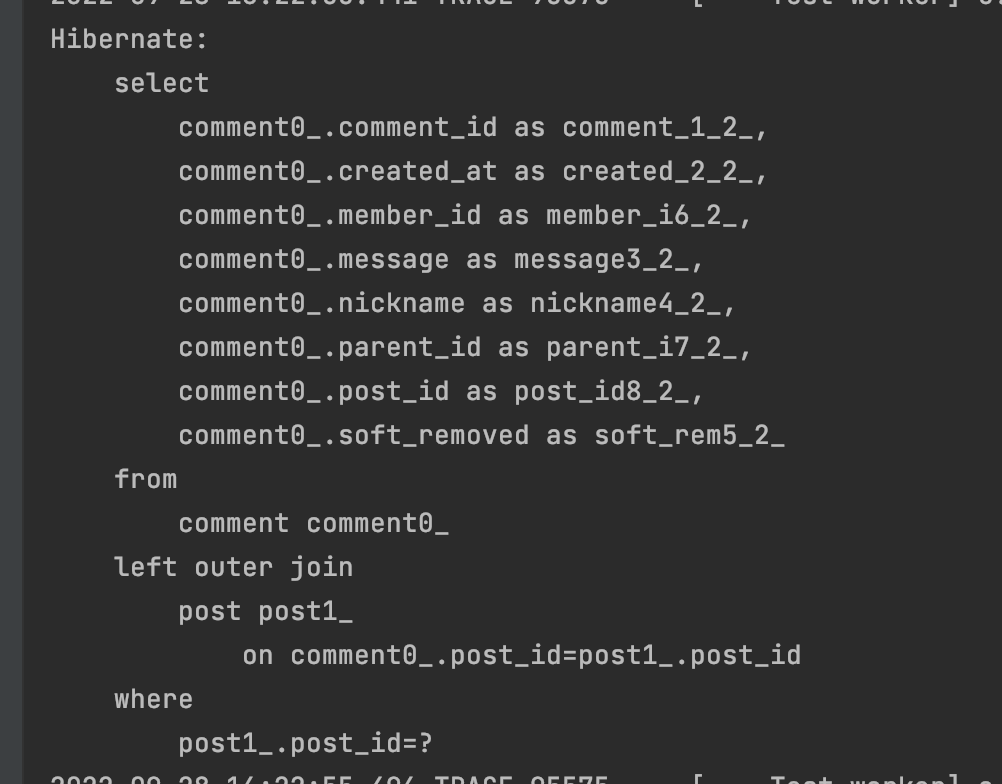
where 절 탐색으로 바로 post_id 를 통해 가져오는 것이 아니라, outer join 으로 post 테이블을 가져온 뒤에 where 절 탐색으로 post 테이블의 post_id 를 통해 데이터를 가져오고 있는 것이다.
왜 이런 쿼리가?...
그 이유는 Spring Data Jpa 쿼리 메서드의 네이밍 특성 때문이다. Spring Data Jpa는 쿼리 메서드의 네이밍에서 parsing 한 프로퍼티를 엔티티 클래스의 필드에서 찾는다.
@Entity public class Comment { @ManyToOne @JoinColumn(name = "post_id") private Post post; }현재 이런 방식으로 Comment 클래스가 작성되어 있는데, 여기서 JoinColumn으로 post_id 를 걸어놨으니 당연히 잘 찾을 것이라고 생각했던것 같다. 하지만, 실상은 엔티티 클래스의 필드를 찾아 가기 때문에 post_id 를 찾지 못하는 것이다.
바꾸어 보자
findAllByPostId 를 findAllByPost 로 바꾸고 다시 쿼리를 보았다.
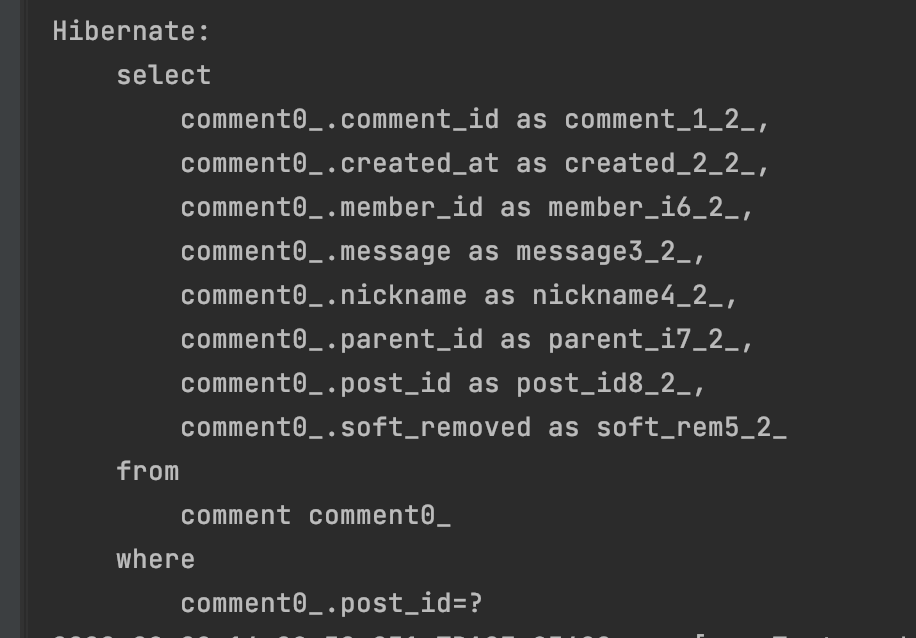
처음에 원했던 where 절 탐색 이용 쿼리가 나오는 것을 확인했다!
이제 이런 방식으로 작성 되어 있던 쿼리 메서드를 바꾸는 일만 남았다. 그런데, 여기서 문제 아닌 문제가 발생했다.
findByPostIdAndMemberId(Long postId, Long memberId) 에서 postId는 post로 리팩터링 할 수 있지만, memberId는 로그인한 사용자의 멤버 객체가 아니라 JWT 토큰에서 추출한 간소화된 정보만 가진 AuthInfo 객체여서 member 객체를 넘겨줄 수 없다. 여기서 선택지 두 개가 생긴다. authInfo의 id를 통해 member 테이블에서 id값으로 member 객체를 찾아와 existsByPostAndMember 에 넣어줄 것인가? 아니면 existsByPostAndMemberId 형식으로 post만 엔티티를 넣고 멤버는 memberId 를 넣는 방식으로 갈 것인가에 대한 선택이다.
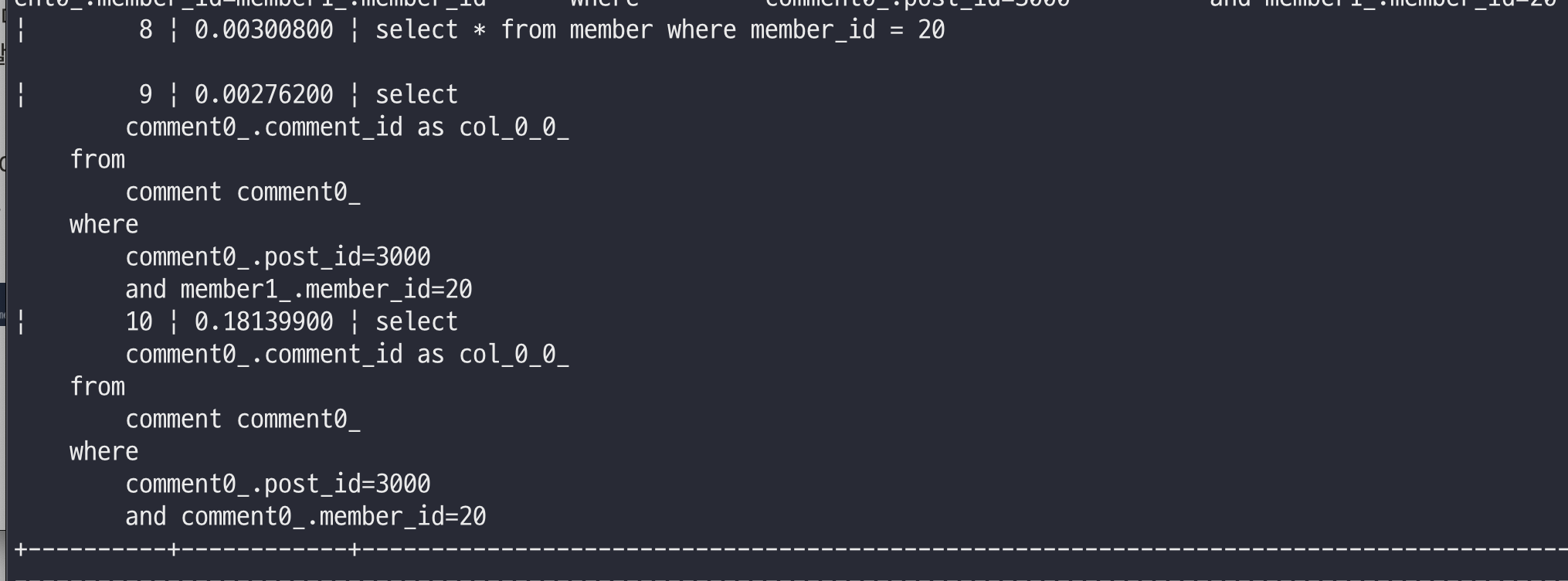

전자의 방법은 쿼리를 두번 실행하는 방법인데, 각각 0.00300800, 0.00276200 으로 합은 0.00577 초 이다.
후자의 방법은 outer join이 두 번 일어나는 방법으로, 1.83154700 초가 나왔다.
쿼리를 두번 실행하는 방식이 훨씬 경제적이다!
또한, comment 는 대댓글 데이터까지 포함하고 있기 때문에 행의 개수가 매우 많은 편에 속한다. 지금 당장은 운영서버에서 의미있는 차이가 발생하지 않지만, comment 테이블의 row가 1000만개 이상이 된다면? left outer join을 했을때는 그 많은 comment 를 풀스캔해야 하지만, member를 찾아온 다음 엔티티를 통해 조회하여 찾게되면 secondary index를 타게 되어 풀스캔을 하지 않아 성능이 비약적으로 좋아지게 될 것이다.
더 나은 방법
굳이 member 객체를 찾아오지 않고 authInfo의 id를 기준으로 jpql을 직접 넣어버리면 된다!
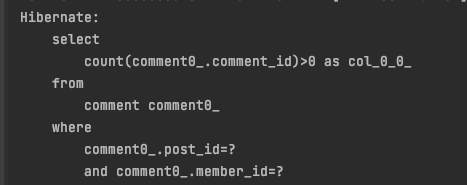
outer join 을 걸지 않고 where 절로 탐색 하는 것을 볼 수 있다.
findByPostIdAndMemberId 는 해결이 되었다.
그런데... existsByPostIdAndMemberId 를 개선하면서 jpql로 exists를 하려고 하니 jpql은 exists 쿼리를 제공하지 않았다. exists 를 구현하기 위해서는 count 조건을 주어 0개 이상일 경우에 대해 체크하는데, 이 때 테이블 풀 스캔이 일어나게 된다.
이를 개선하기 위해서 native sql 의 exists 쿼리를 사용하려 하려는 순간… existsByPostAndMemberId 의 경우 left outer join이 일어나지만, limit이 걸려있어 outer join 전체적으로 일어나기 전에 일치하는 post_id 를 찾으면 탐색을 멈출것 같은데? 라는 생각이 들었다. 궁금하니 바로 수행 시간을 알아보자.
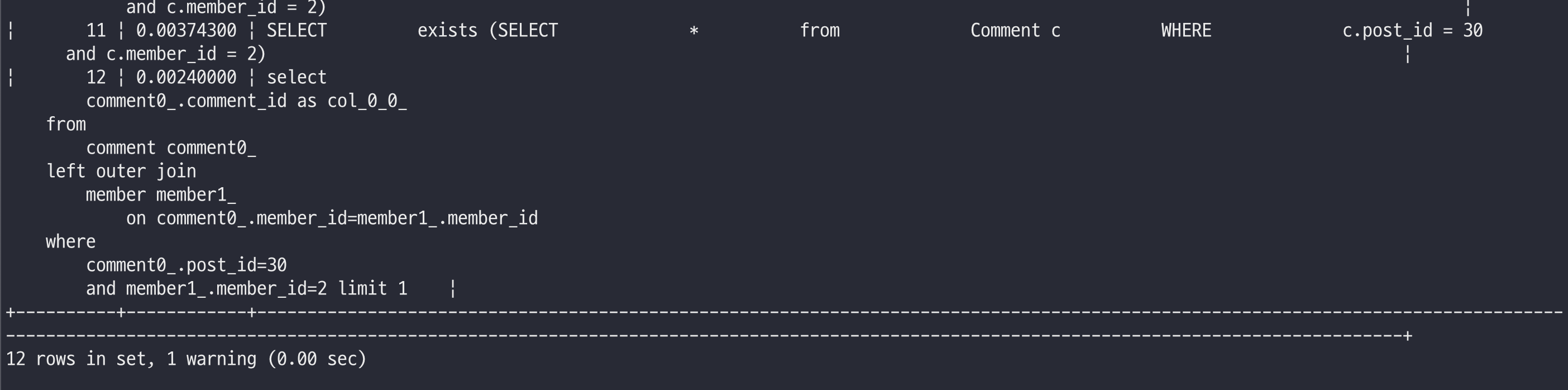
실험 결과, 실제로 비슷한 수행시간을 보여준다. 이 경우에는 무엇을 쓰든 상관 없겠지만, 문자열로 native sql을 적는 것 보다는 jpa의 쿼리 메서드를 그대로 사용하는 것이 낫다고 생각된다.